利用条件传输比较概率分布
Comparing Probability Distributions with Conditional Transport (Huangjie Zheng and Mingyuan Zhou The University of Texas at Austin)
测量两个概率分布之间的差异是统计学和机器学习中的一个基本问题。常用的统计距离包括 Kullback-Leibler (KL)散度、Jensen-Shannon (JS)散度和Wasserstein距离。KL散度要求两个概率分布拥有相同的支撑集,因此如果其中任何一个是概率密度函数 (PDF) 未知的隐式分布,那么 KL 散度通常不适用。GAN最初使用JS散度,但在生成器和判别器之间维持良好平衡非常困难,导致 GAN 的训练非常脆弱。Wasserstein的理论虽好,但在实际计算中,特别是它的对偶形式,为了满足一个严格的数学约束(Lipschitz约束),需要很多技巧,实现起来很麻烦,而且计算出的梯度可能还是有偏差的。如果用它的原始形式,计算成本又非常高。
Conditional Transport
因此,选择引入条件传输 (CT) 作为一种新的散度来量化两个概率分布之间的差异。我们将它们称为源分布和目标分布,并将其概率密度函数 (PDF) 分别表示为 $p_x(x)$ 和 $p_y(y)$。
CT的核心思想非常直观,我们可以用一个物流系统的类比来理解它:
- 真实数据分布 $p_x(x)$:想象成全国各地所有的“发货仓库”。
- 生成数据分布 $p_y(y)$:想象成我们计划建立的“收货仓库”。
我们希望收货仓库的布局 ($p_y(y)$) 和发货仓库的布局 ($p_x(x)$) 尽可能匹配,这样整体物流成本才最低。
CT引入了两个非常重要的概念:双向传输 和 导航器 (Navigator)。
双向传输
不同于只计算单向成本的Wasserstein距离,CT同时考虑了两个方向的成本:
- 前向传输成本 (Forward CT Cost):从“真实仓库”$x$ 发货到 “生成仓库”$y$ 的平均成本。
- 直观意义:这个成本衡量了我们所有的真实数据,是否都能很方便地(低成本地)被我们生成的分布所“覆盖”。如果某个真实数据点(比如一个偏远地区的发货仓库)附近没有任何我们生成的点(收货仓库),那这个点的运输成本就会很高,从而拉高总的前向成本。
- 作用:最小化这个成本,会迫使生成器去“覆盖 (Covering)”真实数据的所有模式。比如,如果真实数据是10个数字的笔迹,生成器就必须学会生成所有0-9的数字,而不能只生成“1”,否则那些“2”到“9”的真实数据就会因为找不到匹配而导致前向成本飙升。这有助于解决GAN中的Mode Covering问题。
- 后向传输成本 (Backward CT Cost):从“收货仓库”$y$ 发货到 “真实仓库”$x$ 的平均成本。
- 直观意义:这个成本衡量了我们生成的每一个数据点,是否都落在了真实数据密集的区域。如果我们生成了一个很奇怪的点(在一个偏远的地方建了个收货仓库),而它周围没有任何真实数据点(发货仓库),那么从它出发的运输成本就会很高。
- 作用:To minimize这个成本,会迫使生成器只在真实数据存在的地方生成数据,避免生成那些“四不像”的垃圾样本。这有助于解决“模式搜寻 (Mode Seeking)”问题,确保生成样本的质量。
In short,Mode Covering 的目标是雨露均沾(覆盖所有数据),Mode Seeking的目标是独宠一人(只关注概率最高的区域)。
Anyway,双向传输非常重要,因为只考虑前向(Mode Covering),可能会导致生成器为了覆盖所有真实样本,生成一些模糊、质量不高的样本(比如把“1”和“7”混合在一起,试图同时覆盖两者)。只考虑后向(模式搜寻),可能会导致Mode Collapse。即生成器发现只生成最简单的、最像真实数据的某一种样本(比如只生成数字“1”)就能让后向成本很低,于是它就放弃学习其他模式了。
CT通过将前向和后向成本加权平均,实现了Mode Covering和Mode Seeking的完美平衡,这是它相比之前方法的一个巨大优势。
Navigator与数学公式解析
CT引入了一个叫做Navigator $\pi(y\mid x)$ 的东西。可以把它想象成一个智能的Google Map,它会告诉你从起点 $x$ 出发,去往各个可能的目标点 $y$ 的“推荐路线”概率。
前向导航器 (Forward Navigator)
\[\pi_\phi(y\mid x) \stackrel{\text{def}}{=} \frac{e^{-d_\phi(x, y)} p_\theta(y)}{\int e^{-d_\phi(x, y')} p_\theta(y') dy'}\]- \(\pi_\phi(y\mid x)\):表示给定一个真实数据点 \(x\) (起点),它被传输到生成数据点 \(y\) (终点) 的条件概率。\(\phi\) 是这个导航器自身的参数(比如一个神经网络的权重)。
- $p_\theta(y)$:是生成分布在 $y$ 点的密度。可以理解为目标点 $y$ 的“热门程度”。一个地方越热门,导航系统就越可能推荐你去。
- $d_\phi(x, y)$:这是一个可学习的距离函数,衡量 $x$ 和 $y$ 的“距离”或“不相似度”。这个距离也是由一个神经网络(参数是$\phi$)算出来的。
- $e^{-d_\phi(x, y)}$:这是将距离转化为了一个“吸引力”分数。距离 $d$ 越小,这个分数就越大,表示 $x$ 和 $y$ 越“亲近”,传输过去的可能性就越高。
- 分母 $\int … dy’$:这是一个归一化项。它把从 $x$ 出发到所有可能的目的地 $y’$ 的“吸引力分数×热门程度”加起来,确保从 $x$ 出发的所有路径概率加起来等于1。
So this formula means that从真实点 $x$ 出发,导航器会优先推荐你去那些本身很热门 ( $p_\theta(y)$ 大) 并且离 $x$ 很近 ( $d_\phi(x, y)$ 小) 的生成点 $y$。
有了Navigator,我们就可以定义前向CT的总成本了: \(C_{\phi, \theta}(\mu \to \nu) = \mathbb{E}_{x \sim p_x(x)} \mathbb{E}_{y \sim \pi_\phi(y\mid x)}[c(x, y)]\)
- $\mathbb{E}_{x \sim p_x(x)}$:表示“对于一个随机从真实数据中抽取的点 $x$…” (在所有发货仓库中平均来看…)
- \(\mathbb{E}_{y \sim \pi_\phi(y\mid x)}\):表示“…再根据我们的导航器 $\pi_\phi(y\mid x)$ 随机选择一个目标点 \(y\) …” (…按照Google Map的推荐路线走…)
- $c(x, y)$:是点对点的运输成本(比如可以是 $x$ 和 $y$ 的欧氏距离)。 前向CT成本就是,我们从所有真实仓库出发,按照导航器的指引发货,所需要付出的平均运输成本。
后向导航器 (Backward Navigator) 和后向成本的定义与前向完全对称,只是把 $x$ 和 $y$ 的角色互换了而已: \(\pi_\phi(x\mid y) \stackrel{\text{def}}{=} \frac{e^{-d_\phi(x, y)} p_x(x)}{\int e^{-d_\phi(x', y)} p_x(x') dx'}\)
现在是从生成点 $y$ 出发,去往那些本身很热门的真实点 $x$ ( $p_x(x)$ 大) 并且离 $y$ 很近的地方。
最后,总CT成本,就是把前向和后向成本简单地平均一下: \(C_{\phi, \theta}(\mu, \nu) \stackrel{\text{def}}{=} \frac{1}{2} C_{\phi, \theta}(\mu \to \nu) + \frac{1}{2} C_{\phi, \theta}(\mu \leftarrow \nu)\)
模型训练的目标:就是调整生成器 $G_\theta$ (决定了 $p_\theta(y)$) 和导航器 $\pi_\phi$ (决定了路径),来minimize这个总的CT成本 $C_{\phi, \theta}(\mu, \nu)$。
摊销式条件传输 (Amortized Conditional Transport, ACT)
Amortized:将一次性巨大的计算成本,分摊到多次小的、可管理的计算中去
ACT的目标就是把理论CT中那个需要积分、需要知道完整分布的复杂计算,变成只需要用一小批(mini-batch)样本就能简单计算的步骤。
1. 问题的根源:连续分布 vs. 离散样本
我们再看一下前向导航器的公式: \(\pi_\phi(y\mid x) = \frac{e^{-d_\phi(x, y)} p_\theta(y)}{\int e^{-d_\phi(x, y')} p_\theta(y') dy'}\)
这个公式是为continuous的概率分布 $p_\theta(y)$ 设计的。但在实际的深度学习训练中,我们没有连续的分布,我们只有从生成器 $G_\theta$ 中采样出来的一批discrete的样本。比如,在一个训练步骤中,我们从真实数据集中随机抽取了 $N$ 个样本,组成一个小批量 ${x_1, x_2, …, x_N}$。同时,我们也让生成器生成了 $M$ 个假样本,组成一个小批量 ${y_1, y_2, …, y_M}$。我们能做的,就是用这些离散的样本点来近似代替完整的连续分布。
2. ACT的解决方案:用样本“投票”
ACT的做法非常intuitive:
- 用真实样本 \(\{x_i\}_{i=1}^N\) 组成的经验分布 $\hat{\mu}_N$ 来近似真实的 $p_x(x)$。
- 用生成样本 \(\{y_j\}_{j=1}^M\) 组成的经验分布 \(\hat{\nu}_M\) 来近似生成的 $p_\theta(y)$。
一个经验分布是什么样的?可以想象,在每个样本点的位置上,我们放上一个权重为 $1/N$(或 $1/M$)的“沙粒”,其他地方都是空的。
现在,我们把连续的 $p_\theta(y)$ 换成离散的 ${y_j}_{j=1}^M$。原来那个需要积分的导航器公式,就变成了一个简单的、基于样本的“投票”公式。
离散的前向导航器 \(\hat{\pi}_M(y_j\mid x, \phi) \stackrel{\text{def}}{=} \frac{e^{-d_\phi(x, y_j)}}{\sum_{l=1}^M e^{-d_\phi(x, y_l)}}\)
让我们来解析这个ACT的核心公式:
- $\hat{\pi}_M(y_j\mid x, \phi)$:给定一个真实点 $x$,它被传输到某一个特定的生成样本 $y_j$ 的概率。
- $e^{-d_\phi(x, y_j)}$:分子是 $x$ 和 $y_j$ 之间的“吸引力”分数。
- $\sum_{l=1}^M e^{-d_\phi(x, y_l)}$:分母是 $x$ 对当前批次中所有生成样本 ${y_1, …, y_M}$ 的“吸引力”分数总和。
So this formula means that给定一个真实点 $x$,它会以一个概率被运送到生成样本 $y_j$。这个概率的大小,取决于 $y_j$ 相对于批次中所有其他生成样本,离 $x$ 有多“近”。这本质上就是一个 Softmax 函数。它在所有可用的目标点 ${y_l}$ 上进行了一次加权选择。
有了这个离散的Navigator,前向ACT成本的计算也变得非常简单: 前向ACT的点对批次成本 \(C_{\phi, \theta}(x \to \hat{\nu}_M) \stackrel{\text{def}}{=} \sum_{j=1}^M c(x, y_j) \hat{\pi}_M(y_j\mid x, \phi)\)
This formula means that从一个真实点 $x$ 出发,到当前这批生成样本 ${y_j}$ 的期望运输成本。它就是把去往每个 $y_j$ 的成本 $c(x, y_j)$ 乘以去往该点的概率 $\hat{\pi}_M(y_j\mid x, \phi)$,然后加起来。
后向ACT 的公式也是完全对称的,是从一个生成点 $y$ 到当前这批真实样本 ${x_i}$ 的期望运输成本。
3. ACT的总成本与无偏估计量
我们定义了ACT问题:\(\min_{\phi, \theta} \{ C_{\phi, \theta}(\mu, \nu, N, M) \}\)
现在我们有了计算一个点到一个批次成本的方法。那么,对于一整个批次的真实数据和生成数据,总的ACT成本怎么算呢?
总ACT成本的定义 \(C_{\phi, \theta}(\mu, \nu, N, M) = \frac{1}{2} \mathbb{E}_{y_{1:M}}[C_{\phi, \theta}(\mu \to \hat{\nu}_M)] + \frac{1}{2} \mathbb{E}_{x_{1:N}}[C_{\phi, \theta}(\hat{\mu}_N \leftarrow \nu)]\)
- 第一项是前向成本:对于所有可能的生成批次 ${y_j}$,我们计算从整个真实分布 $\mu$ 到这个批次的平均成本。
- 第二项是后向成本:对于所有可能的真实批次 ${x_i}$,我们计算从整个生成分布 $\nu$ 到这个批次的平均成本。
这个公式还是理论上的,因为我们仍然不知道完整的分布 $\mu$ 和 $\nu$。但幸运的是,我们可以基于当前手里的小批量 ${x_i}$ 和 ${y_j}$,构造出一个无偏的样本估计量 (unbiased sample estimator)。
这就是论文中最重要的实践公式之一: ACT成本的无偏估计量 \(\mathcal{L}_{\phi, \theta}(x_{1:N}, y_{1:M}) = \sum_{i=1}^N \sum_{j=1}^M c(x_i, y_j) \times (\frac{1}{2N}\hat{\pi}_M(y_j\mid x_i, \phi) + \frac{1}{2M}\hat{\pi}_N(x_i\mid y_j, \phi))\)
这个公式就是我们最终在代码里计算损失函数 (Loss Function) 的依据。让我们拆解它:
- $\sum_{i=1}^N \sum_{j=1}^M$:这是一个双重循环,遍历了当前批次中每一对真实样本 $x_i$ 和生成样本 $y_j$。
- $c(x_i, y_j)$:计算这对样本之间的点对点运输成本。
- $\frac{1}{2N}\hat{\pi}_M(y_j\mid x_i, \phi)$:这是前向部分。对于给定的 $x_i$,我们计算它被运到 $y_j$ 的概率,然后除以 $N$ (在所有真实样本上平均) 和 2 (前向后向各占一半)。
- $\frac{1}{2M}\hat{\pi}_N(x_i\mid y_j, \phi)$:这是后向部分。对于给定的 $y_j$,我们计算它被运到 $x_i$ 的概率,然后除以 $M$ (在所有生成样本上平均) 和 2。
这个公式的优势在于:
- 完全可计算:它只涉及当前小批量中的样本,没有任何积分或未知的分布。
- 梯度直接:我们可以直接对这个损失函数 $\mathcal{L}$ 求关于模型参数 $\theta$ 和导航器参数 $\phi$ 的梯度,然后用梯度下降来更新模型。
- 无偏 (Unbiased):这是一个非常好的数学性质。它意味着,虽然我们每次只看一小批样本,但长期来看,我们优化的方向是正确的,平均而言它等于优化那个理论上的、真实的CT成本。这是相比WGAN的一个巨大优势,WGAN的样本梯度通常是有偏的。
4. 引入“评判家”(Critic)来提升效果
到目前为止,我们假设点对点成本 $c(x, y)$ 和导航器距离 $d_\phi(x, y)$ 是直接在原始数据(比如图像的像素)上计算的。但论文作者指出,对于高维数据(如图像),像素级别的距离往往不能反映我们人眼感知的“语义”距离。一张“猫”的图片和一张“狗”的图片,在像素上可能差异巨大,也可能很小,这不靠谱。
因此,论文引入了一个评判家 (Critic) $T_\eta(\cdot)$,这是一个由参数 $\eta$ 控制的深度神经网络。它的作用是:
- 提取特征:把原始的高维数据 $x$(比如一张 64x64x3 的图片)映射到一个低维的、更有意义的特征空间 (feature space) 中去,得到特征向量 $T_\eta(x)$。
- 让距离计算更合理:我们不再直接比较 $x$ 和 $y$,而是比较它们的特征向量 $T_\eta(x)$ 和 $T_\eta(y)$。 基于评判家的成本函数 \(c_\eta(x, y) = 1 - \cos(T_\eta(x), T_\eta(y))\) 这里使用了余弦相异性 (cosine dissimilarity) 来计算成本。两个特征向量的方向越接近,余弦相似度越接近1,成本 $c_\eta$ 就越接近0。
同样,导航器中的距离 $d$ 也在特征空间中计算:$ d_{\phi, \eta}(x, y) = d_\phi(\frac{T_\eta(x)}{\mid \mid T_\eta(x)\mid \mid }, \frac{T_\eta(y)}{\mid \mid T_\eta(y)\mid \mid }). $
对抗性训练 (Adversarial Training)
现在我们有三个玩家了:
- 生成器 $G_\theta$ 和 导航器 $\pi_\phi$:它们是一伙的,目标是生成好的样本并规划好路径,来最小化最终的ACT成本 $\mathcal{L}$。
- 评判家 $T_\eta$:它是对抗方,目标是调整特征空间,最大化ACT成本 $\mathcal{L}$。它会努力地把真实样本的特征和生成样本的特征在特征空间中推得尽可能远,从而让成本变高。
总之,给定训练数据 $\mathcal{X}$,为了训练生成器 $G_\theta$、前向导航器 $\pi_\phi(y\mid x)$、后向导航器 $\pi_\phi(x\mid y)$ 和评判家 $T_\eta$,我们建议解决一个最小-最大问题: \(\min_{\phi, \theta} \max_\eta \mathbb{E}_{x_{1:N} \stackrel{\text{iid}}{\sim} \mathcal{X}, \epsilon_{1:M} \stackrel{\text{iid}}{\sim} p(\epsilon)} [\mathcal{L}_{\phi, \theta, \eta}(x_{1:N}, \{G_\theta(\epsilon_j)\}_{j=1}^M)]\)
这种min-max博弈使得评判家学会了如何最有效地分辨真假样本的特征,从而为生成器和导航器提供了更强大、更有意义的梯度信号。
论文证明,即使这个评判家 $T_\eta$ 训练得不那么完美,ACT成本的梯度仍然是无偏的。这解决了训练WGAN时的一个核心痛点,即必须把评判家训练得非常好(接近最优),否则生成器的梯度就会不准。ACT则没有这个烦恼,大大增强了训练的稳定性和鲁棒性。
实验
论文的实验部分可以分为三个层次:
- 玩具实验 (Toy Experiments):在简单的一维和二维数据集上,直观地、可视化地展示CT/ACT的核心机制和优点。
- 消融研究 (Ablation Study):控制变量,深入探究ACT不同组成部分(如前向/后向成本、评判家)的作用。
- 真实图像实验 (Real-world Image Experiments):在像CIFAR-10这样复杂的真实图像数据集上,与当前主流的GAN模型(SOTA, State-of-the-art)进行性能对比。
1. 玩具实验
A. 一维正态分布实验

这组图的实验设置是:
- 真实分布 $\mu$:标准正态分布 $\mathcal{N}(0, 1)$,即均值为0,方差为1。
- 生成分布 $\nu$:一个可学习的正态分布 $\mathcal{N}(\theta, e^\phi)$,其中我们要学习的参数是均值 $\theta$ 和方差的对数 $\phi$。
- 目标:通过优化,让 $\theta \to 0$ 且 $\phi \to 0$ (即方差 $e^\phi \to 1$)。
B. 一维/二维混合高斯分布实验 (图2, 图3)
- 目标:真实数据是混合在一起的几个高斯分布(比如两个或八个“沙堆”)。这是模拟多模式 (multi-modal) 数据的经典场景,也是测试模型是否会模式崩塌的“试金石”。
-
图2 (训练过程):

展示了ACT如何一步步学习一个双峰分布。一开始只学会了一个峰(模式崩塌),但随着导航器越来越准,它能“感知”到另一个被遗漏的模式区域成本很高,从而引导生成器去探索那个区域,最终两个峰都学会了。
-
图3 (对比实验):这个实验比较了ACT和Wasserstein距离 (WGAN) 在不同批量大小 (mini-batch size) 下的性能。
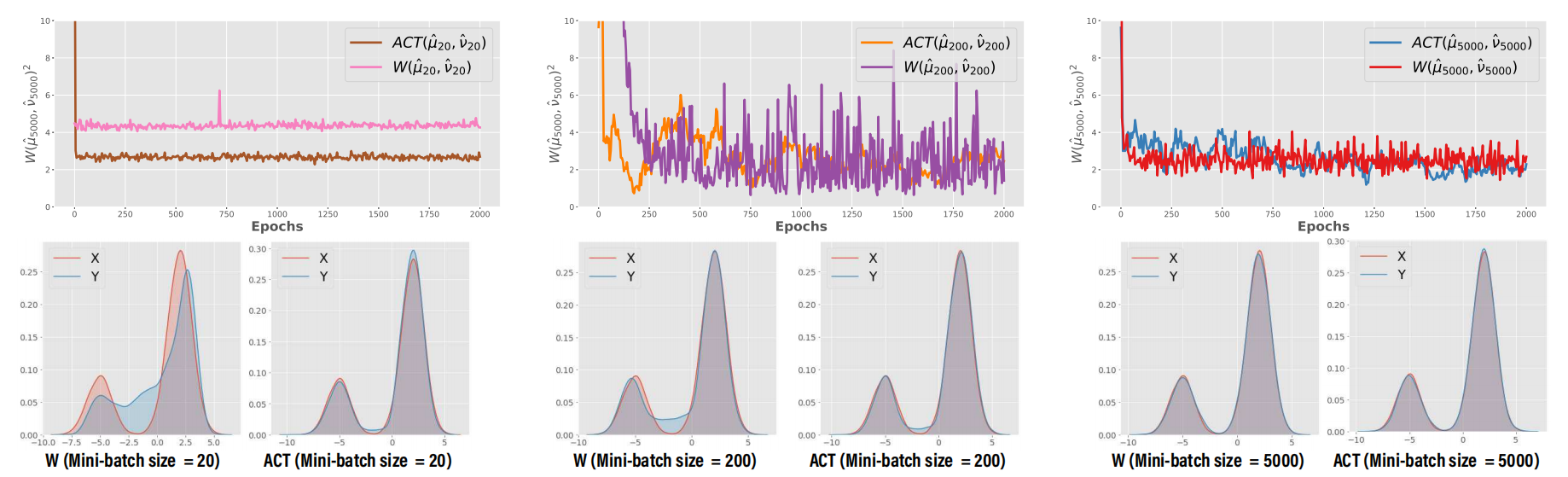
- 当批量很大时(N=5000),两者效果都很好。
- 当批量变小时(N=200, N=20),WGAN的性能急剧下降,几乎学不到东西了。而ACT的性能几乎不受影响,依然非常出色。
- 为什么会这样? WGAN的传输计划是为每个小批量“临时”计算的,小批量样本少,信息量不足,算出来的计划就非常不稳定。而ACT的导航器是全局学习的,它在所有见过的批次上不断更新和积累知识,所以它的“导航”能力不依赖于单个小批量的大小,表现得非常鲁棒 (robust)。这在计算资源有限时是一个巨大的优势。
2. 消融实验
A. 前向 vs. 后向的平衡
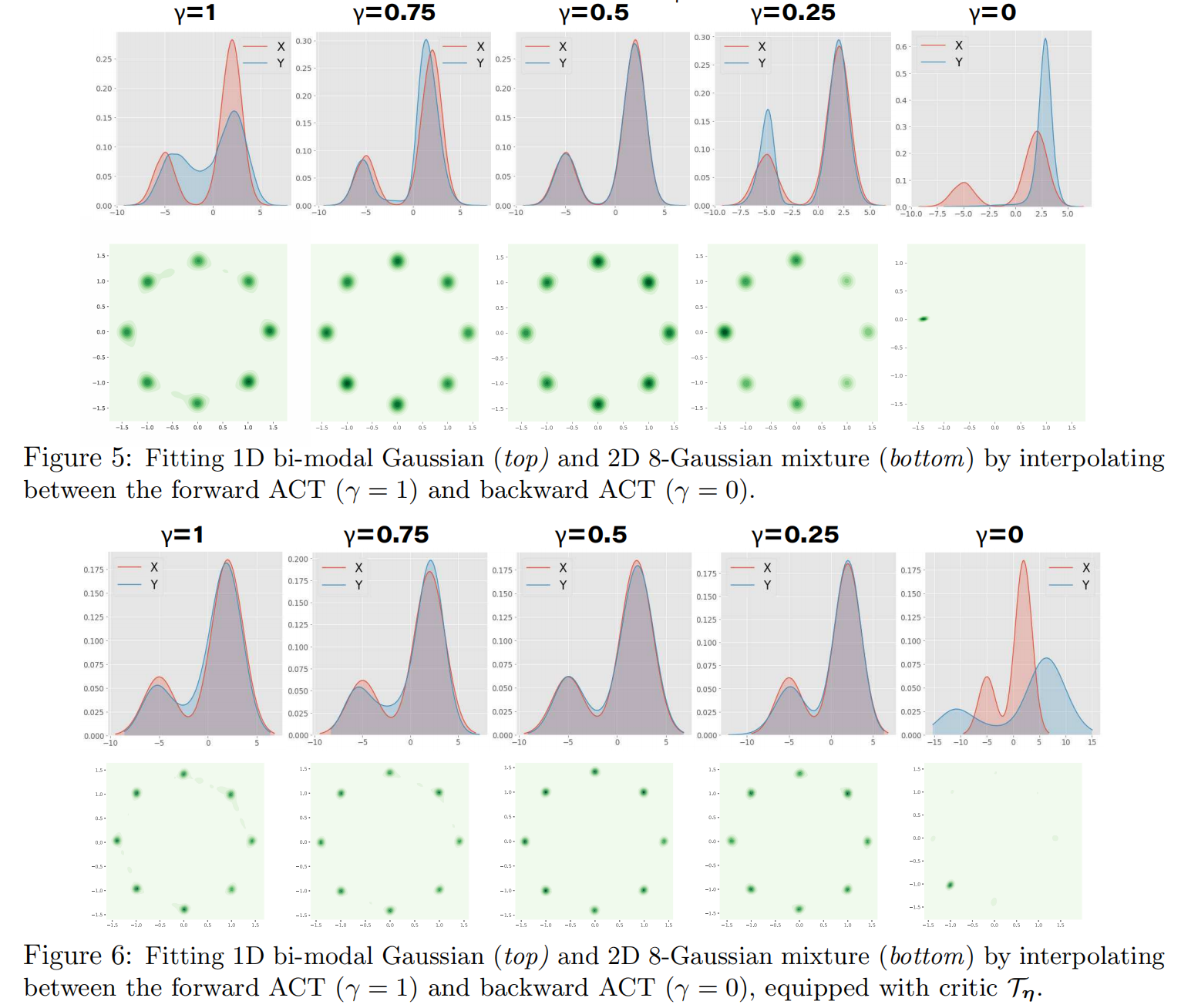
- 目标:通过一个插值系数 $\gamma$ 来控制前向成本和后向成本的权重,看看对生成结果有什么影响。
- $\gamma=1$:只用前向成本。
- $\gamma=0$:只用后向成本。
- $\gamma=0.5$:标准ACT,两者平衡。
- 发现:
- 在二维的8-高斯数据集上,当$\gamma=1$(纯前向)时,模型试图覆盖所有8个模式,但在模式之间生成了很多垃圾样本,质量很差。
- 当$\gamma=0$(纯后向)时,模型发生了严重的模式崩塌,只学会了其中一两个模式。
- 当$\gamma$在0.25到0.75之间时,效果都很好,特别是$\gamma=0.5$时,既没有模式崩塌,样本质量也很高。
- 结论:这个实验再次证明了双向平衡是ACT成功的关键。同时,它也提供了一个可调参数 $\gamma$,让用户可以根据实际需求微调模型是更偏向“多样性”(覆盖)还是“高质量”(搜寻)。
B. 对抗性ACT的验证
- 图6显示,即使加入了对抗性的评判家 (Critic),上述的平衡关系依然成立,并且$\gamma=0.5$仍然是最佳选择。这说明评判家的引入并没有破坏ACT原有的良好特性,而是增强了它。
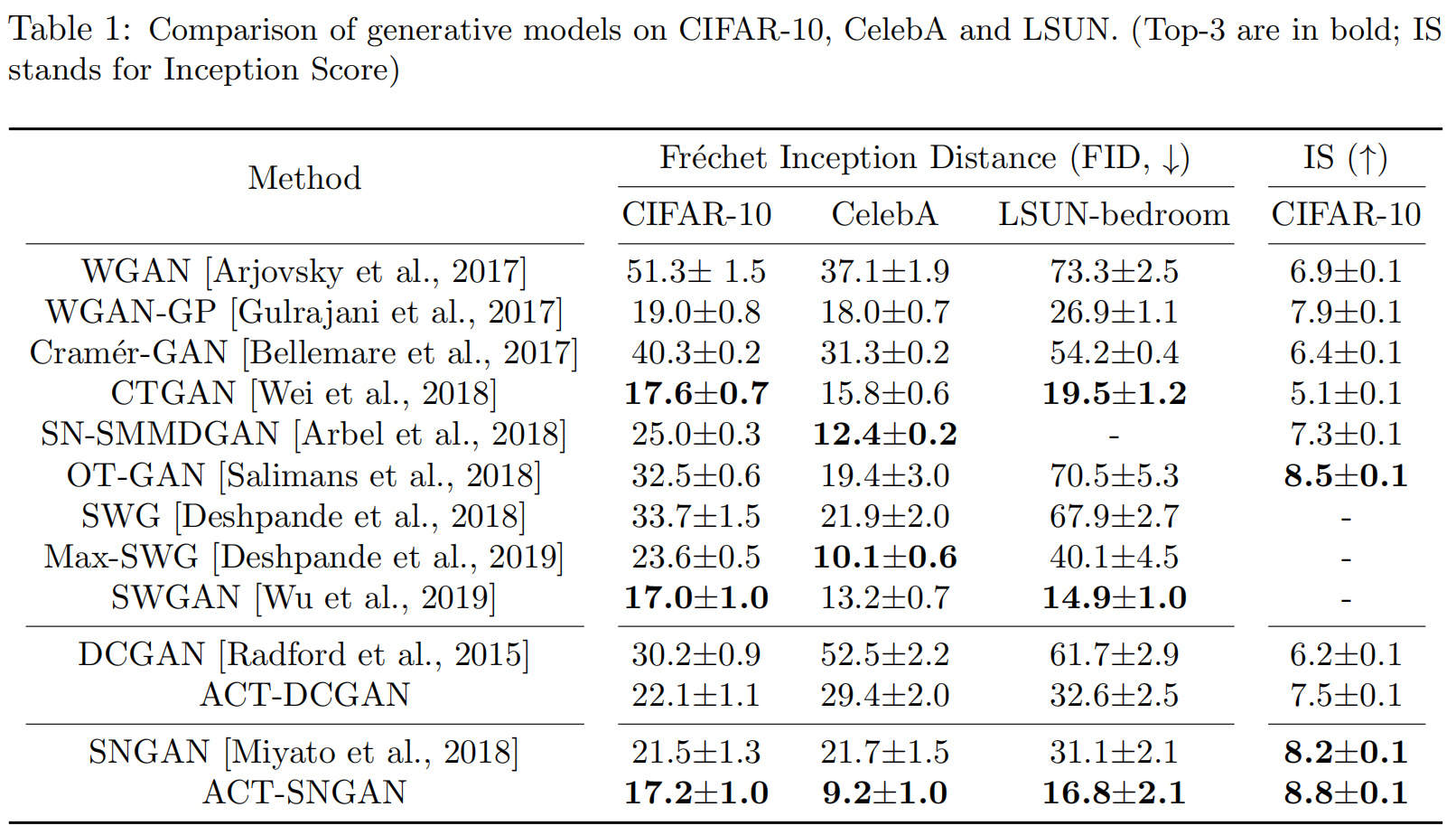
3. 真实图像实验
- 目标:在CIFAR-10(小图片)、CelebA(人脸)、LSUN(场景)这些标准数据集上,将ACT应用于经典的GAN架构(如DCGAN, SNGAN),并与原始模型以及其他先进模型进行性能比较。
- 评价指标:
- FID (Fréchet Inception Distance):目前最主流的GAN评价指标,分数越低越好,代表生成图像的质量和多样性都与真实图像更接近。
- IS (Inception Score):一个较早的指标,分数越高越好,主要衡量生成图像的清晰度和多样性。
- 核心发现: