利用链式法则和贝叶斯定理比较概率分布
Exploiting Chain Rule and Bayes’ Theorem to Compare Probability Distributions
对于Comparing Probability Distributions with Conditional Transport,我们将原来的Navigator思想,升华到了一个更根本的概率论高度,直接与概率链式法则 (Chain Rule) 和 贝叶斯定理 (Bayes’ Theorem) 这两大基石联系起来。
理论框架——链式法则与贝叶斯定理
如何用概率论的基本法则来构建两个分布之间的关联?
1. 概率链式法则 (Chain Rule)
概率链式法则是概率论中最基本的公式之一,它告诉我们如何分解一个联合概率分布。对于两个随机变量 $x$ 和 $y$,它们的联合分布 $\pi(x, y)$ 可以用两种方式分解:
- 方式一(前向分解):$\pi(x, y) = p_x(x) \times \pi(y\mid x)$
- 方式二(后向分解):$\pi(x, y) = p_y(y) \times \pi(x \mid y)$
我们想要构建一个连接真实分布 $p_x(x)$ 和生成分布 $p_y(y)$ 的“桥梁”,这个桥梁就是联合分布 $\pi(x, y)$。链式法则告诉我们有两种建桥的方式:
- 前向建桥(Forward CT):我们先从真实世界中抽取一个样本 $x$(遵循 $p_x(x)$),然后基于这个 $x$,我们再通过一个条件分布 $\pi(y\mid x)$ 来选择一个与之匹配的生成样本 $y$。
- 后向建桥(Backward CT):我们先从生成器中抽取一个样本 $y$(遵循 $p_y(y)$),然后基于这个 $y$,我们再通过一个条件分布 $\pi(x\mid y)$ 来寻找一个与之匹配的真实样本 $x$。
2. 贝叶斯定理 (Bayes’ Theorem)
现在的问题是,那个条件分布 $\pi(y\mid x)$(我们之前称之为Navigator)到底应该长什么样?它不能是随便一个分布,它必须同时体现出真实样本 $x$ 和生成分布 $p_y(y)$ 的信息。
作者选择用贝叶斯定理来定义它。
我们先复习一下贝叶斯定理的经典形式:
\[\text{后验概率} \propto \text{似然} \times \text{先验概率}\] \[P(\text{原因}\mid \text{结果}) \propto P(\text{结果}\mid \text{原因}) \times P(\text{原因})\]对于前向传输 $\pi(y\mid x)$,我们可以这样理解:
- 问题:给定一个已观测到的真实数据 $x$(结果),我们想要推断它最可能匹配的生成数据 $y$(原因)的概率分布。
- 先验概率 (Prior):在我们看到任何真实数据 $x$ 之前,我们对 $y$ 的“先入为主”的看法是什么?很简单,我们认为 $y$ 应该来自于生成器的分布,所以先验就是 $p_y(y)$。这代表了生成器本身生成各个 $y$ 的“热门程度”。
- 似然 (Likelihood):如果一个生成数据真的是 $y$,那么它和我们观测到的真实数据 $x$ “长得像”的可能性有多大?作者将这个“可能性”定义为一个与距离相关的函数,即似然 $\propto e^{-d_\phi(x, y)}$。这里的 $d_\phi(x,y)$ 依然是那个可学习的距离函数。两个点离得越近,似然就越大。
- 后验概率 (Posterior):结合了先验和似然之后,我们得到的更新后的概率分布,就是我们的条件分布 $\pi(y\mid x)$。
把它们整合起来,就得到了论文中的公式(1):
\[\pi_\gamma(y\mid x) = \frac{e^{-d_\phi(x, y)} p_y(y)}{Q(x)}, \quad \text{其中 } Q(x) = \int e^{-d_\phi(x, y')} p_y(y') dy'\]Q(x)是归一化常数
这个公式现在有了贝叶斯解释: 给定一个真实样本 $x$,它将被传输到一个生成样本 $y$ 的概率(后验),正比于 “$y$ 本身作为生成样本的普遍性(先验)” 与 “$y$ 和 $x$ 在特征上的相似性(似然)” 的乘积。
方法的核心机制
有了这个新框架,我们再来看CT的成本函数。
1. 前向与后向CT成本
前向CT成本 (公式2):
\[C(X \to Y) = \mathbb{E}_{x \sim p_x(x)} \mathbb{E}_{y \sim \pi(y\mid x)} [c(x,y)]\]它的含义是:我们按照前向建桥方式 $\pi(x, y) = p_x(x) \pi(y \mid x)$ 构建的联合分布,计算在该分布下,点对成本 $c(x,y)$ 的期望值。
- 与Mode-Covering的联系:论文在这里明确指出了它和KL散度的深刻联系。最小化这个成本,其效果类似于最小化 KL散度 \(KL(p_x \vert \vert p_y)\)。KL散度的性质是,只要某个地方 $p_x(x) > 0$,为了让KL散度不为无穷大,就必须有 $p_y(x) > 0$。也就是说,真实数据存在的地方,生成数据也必须存在。这正是“模式覆盖”的数学本质!
后向CT成本 (公式4): \(C(X \leftarrow Y) = \mathbb{E}_{y \sim p_y(y)} \mathbb{E}_{x \sim \pi(x\mid y)} [c(x,y)]\) 它的含义是:我们按照后向建桥方式 $\pi(x, y) = p_y(y) \pi(x \mid y)$ 构建的联合分布,计算成本的期望值。
- 与模式搜寻 (Mode-Seeking) 的联系:同样,最小化这个成本,其效果类似于最小化反向KL散度 \(KL(p_y \vert \vert p_x)\)。反向KL散度允许在某些地方 $p_y(x)=0$ 即使 $p_x(x)>0$。也就是说,生成的数据可以只专注于真实数据中密度最高、最典型的区域,而忽略那些边缘、不典型的区域。这正是“模式搜寻”和可能导致“模式崩塌”的数学本质。
2. 平衡参数 $\rho$ (rho)
总CT成本 (公式5):
\[C_\rho(X, Y) := \rho C(X \to Y) + (1-\rho)C(X \leftarrow Y)\]- $\rho \in$ 是一个可以调节的超参数。
- 当 $\rho=1$ 时,模型只关心模式覆盖(可能会生成模糊图像)。
- 当 $\rho=0$ 时,模型只关心模式搜寻(很可能发生模式崩塌)。
- 当 $\rho=0.5$ 时(默认值),模型在两者之间取得平衡。
3. 基于共轭性的解析条件分布
在进入充满不确定性的现实世界(用样本近似)之前,作者先创建了一个理想化的沙盒。在这个沙盒里,所有的问题都有解析解 (analytic solution),也就是说,我们可以用漂亮的数学公式直接把所有东西算出来,而不需要任何近似。
这个沙盒的作用是:
- 验证理论:在一个可以精确计算的环境中,验证我们之前关于模式覆盖/搜寻的猜想是否正确。
- 提供洞察:观察在这个理想环境中,各个参数是如何相互作用、共同达到最优解的,从而为理解更复杂的情况提供宝贵的直觉。
要获得解析解,我们需要一个特殊的数学性质,叫做共轭性 (Conjugacy)。在贝叶斯统计中,“共轭”指的是先验分布 (Prior) 和后验分布 (Posterior) 属于同一个概率分布家族。
回忆一下我们的前向Navigator公式(贝叶斯公式): \(\pi(y\mid x) \propto \underbrace{p_y(y)}_{\text{先验}} \times \underbrace{e^{-d_\phi(x, y)}}_{\text{似然}}\)
如果我们的先验分布 $p_y(y)$ 和似然函数 $e^{-d_\phi(x, y)}$ 的形式“很搭”,使得它们的乘积(后验分布 $\pi(y\mid x)$)依然保持着和先验 $p_y(y)$ 类似的数学形式,我们就称它们是共轭的。
最经典的共轭例子就是正态分布(高斯分布)。 如果先验是正态分布,似然函数也是正态分布的形式,那么后验分布也必然是正态分布。
接下来,利用正态分布的共轭性,得到:
公式(6): 单变量正态分布的例子
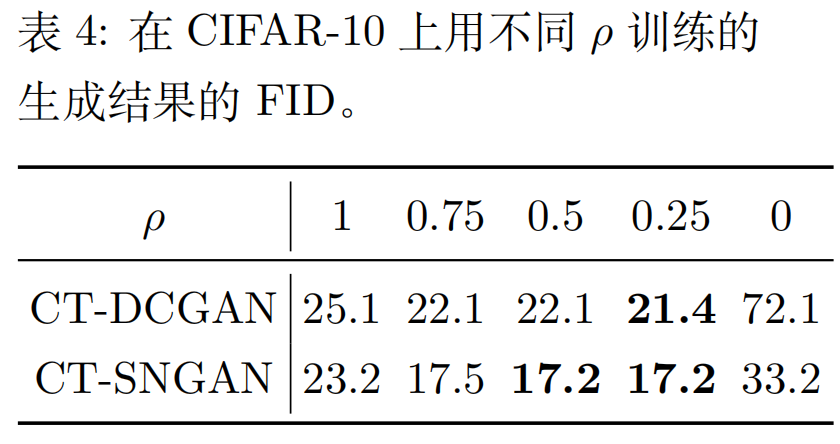
- 源分布 (真实):$p_x(x) = \mathcal{N}(0, 1)$,一个标准正态分布。
- 目标分布 (生成):$p_y(y) = \mathcal{N}(0, e^\theta)$,一个均值为 0,方差为 $e^\theta$ 的正态分布。
- 距离函数:$d_\phi(x, y) = \frac{(x-y)^2}{2e^\phi}$。
- 成本函数:$c(x, y) = (x-y)^2$。
为什么这个设置是“理想”的? 因为这里的似然函数形式 $e^{-d_\phi(x, y)} = e^{-\frac{(x-y)^2}{2e^\phi}}$ 正好也是一个(未归一化的)正态分布的形式,而我们的先验 $p_y(y)$ 也是正态分布。正态乘以正态,结果还是正态。
因此,在这个设置下,前向导航器 $\pi(y\mid x)$ 和后向导航器 $\pi(x\mid y)$ 都可以被精确地计算出来,它们的结果也都是正态分布。论文在附录C中给出了详细的推导,最终得到:
- 前向导航器:$\pi(y\mid x) = \mathcal{N}(\sigma(\phi-\theta)x, \sigma(\phi-\theta)e^\phi)$
- 后向导航器:$\pi(x\mid y) = \mathcal{N}(\sigma(-\phi)y, \sigma(\phi))$
- 前向成本:$C(X \to Y) = \sigma(\phi-\theta)(e^\theta + \sigma(\phi-\theta))$
- 后向成本:$C(X \leftarrow Y) = \sigma(\phi)(1 + \sigma(\phi)e^\theta)$
这里的 $\sigma(\alpha) = 1/(1+e^{-\alpha})$ 是Sigmoid函数。在这个沙盒里,所有东西都有明确的数学表达式。
同时,作者引入了一个新的指标 $D(X, Y)$ 来定量地描述目标分布 $p_y$ 相对于源分布 $p_x$ 的行为倾向。
**定义: **\(D(X, Y) = KL(p_x \vert \vert p_y) - KL(p_y \vert \vert p_x)\)
即前向KL散度与反向KL散度之差。
- 如果 $D(X, Y) < 0$:意味着 $KL(p_x \vert \vert p_y) < KL(p_y \vert \vert p_x)$。这表明,从KL散度的角度看,“让$p_y$覆盖$p_x$”比“让$p_y$被$p_x$覆盖”要“容易”得多。这对应于模式覆盖 (mode-covering) 行为。
- 如果 $D(X, Y) > 0$:意味着 $KL(p_y \vert \vert p_x)$ 更小。这对应于模式搜寻 (mode-seeking) 行为。
在我们的沙盒例子中,这个 $D(X, Y)$ 也可以被精确计算出来: \(D(X, Y) = \dots = \theta - \sinh(\theta)\) 其中 $\sinh(\theta)$ 是双曲正弦函数。
- 当 $\theta > 0$(生成分布的方差大于真实分布)时,$D(X, Y) < 0$,表现为模式覆盖。
- 当 $\theta < 0$(生成分布的方差小于真实分布)时,$D(X, Y) > 0$,表现为模式搜寻。
给定经验样本的近似CT
我们需要用已经获得的随机样本来构建真实分布的近似。
在每个训练步骤(iteration)中,我们都会有一个小批量(mini-batch)的数据:
- 一个从真实数据集中无放回抽样得到的批量:$\mathcal{X}_N = {x_1, x_2, \dots, x_N}$
- 一个通过生成器 $G_\theta$ 从随机噪声 $\epsilon_j$ 生成的批量:$\mathcal{Y}_M = {y_1, y_2, \dots, y_M}$
我们可以用这些样本来构建两个经验概率分布 (Empirical Probability Distributions)。
公式(7): 真实数据的经验分布 \(\hat{p}_{\mathcal{X}_N}(x) = \frac{1}{N} \sum_{i=1}^N \delta(x - x_i)\)
公式(8): 生成数据的经验分布 \(\hat{p}_{\mathcal{Y}_M}(y) = \frac{1}{M} \sum_{j=1}^M \delta(y - y_j)\)
现在,我们的核心策略就是:在理论CT的所有公式中,用这些离散的经验分布 \(\hat{p}_{\mathcal{X}_N}\) 和 \(\hat{p}_{\mathcal{Y}_M}\) 来替换掉我们未知的、连续的真实分布 \(p_x\) 和 \(p_y\)。
这个替换策略带来的第一个美妙结果,就是大大简化了导航器的计算。让我们以前向导航器为例。
$Q(x) = \int e^{-d_\phi(x,y’)} p_y(y’) dy’$。
现在,我们将 \(p_y(y')\) 替换为经验分布 \(\hat{p}_{\mathcal{Y}_M}(y') = \frac{1}{M} \sum_{j=1}^M \delta(y' - y_j)\)。
\[Q(x) \approx \int e^{-d_\phi(x,y')} \left( \frac{1}{M} \sum_{j=1}^M \delta(y' - y_j) \right) dy' = \frac{1}{M} \sum_{j=1}^M e^{-d_\phi(x, y_j)}\]于是,对于一个给定的源点 $x$,它被传输到某一个特定的生成样本 $y_j$ 的(近似)条件概率,根据贝叶斯定理,就是:
\[\hat{\pi}(y_j \mid x) = \frac{\text{似然} \times \text{先验}}{\text{证据}} = \frac{e^{-d_\phi(x, y_j)} \times \hat{p}_{\mathcal{Y}_M}(y_j)}{\sum_{l=1}^M e^{-d_\phi(x, y_l)} \hat{p}_{\mathcal{Y}_M}(y_l)} = \frac{e^{-d_\phi(x, y_j)} \times (1/M)}{\sum_{l=1}^M e^{-d_\phi(x, y_l)} \times (1/M)} = \frac{e^{-d_\phi(x, y_j)}}{\sum_{l=1}^M e^{-d_\phi(x, y_l)}}\]这正是论文中的公式(9)所定义的离散前向导航器 $\hat{\pi}_M(y_j\mid x, \phi)$。
- $\hat{\pi}_M(y_j\mid x, \phi)$:这个符号代表,给定一个源点 $x$ 和一个包含 $M$ 个生成样本的批量 $\mathcal{Y}_M$,点 $x$ 被传输到该批量中第j个样本 $y_j$ 的概率。
- Softmax形式:这个公式的形式是一个标准的Softmax函数。它计算了点 $x$ 与批量中所有生成样本 ${y_l}$ 之间的相似度(由 $e^{-d_\phi}$ 衡量),然后将这些相似度进行归一化,得到一个概率分布。这在计算上非常高效和稳定。
同样地,我们也可以得到离散后向导航器 $\hat{\pi}_N(x_i\mid y, \phi)$,它计算的是从一个给定的目标点 $y$ 到真实批量中第 $i$ 个样本 $x_i$ 的概率。
有了离散的导航器,我们就可以来近似CT成本了。
近似前向CT成本 (公式10)
\[\mathcal{C}_{\phi,\theta}(X \rightarrow \hat{Y}_M) = \mathbb{E}_{\boldsymbol{y}_{1:M} \overset{i.i.d}{\sim} p_Y(\boldsymbol{y};\theta)} \mathbb{E}_{\boldsymbol{x} \sim p_X(\boldsymbol{x})} \left[ \sum_{j=1}^{M} c(\boldsymbol{x}, \boldsymbol{y}_j)\hat{\pi}_M(\boldsymbol{y}_j \mid \boldsymbol{x}, \phi) \right])\]近似后向CT成本 (公式11) 的定义是完全对称的。
最后,我们将这两者结合起来,就得到了近似的总CT成本 (公式12):
\[C_{\phi, \theta, \rho}(\hat{X}_N, \hat{Y}_M) = \rho C_{\phi, \theta}(X \to \hat{Y}_M) + (1-\rho)C_{\phi, \theta}(\hat{X}_N \leftarrow Y)\]这个公式仍然包含期望,还不是我们最终的损失函数。最终的损失函数是这个期望的无偏样本估计 (unbiased sample estimate)。
最终的损失函数 (公式13)
通过对公式(12)进行蒙特卡洛近似(即用我们当前手头的一个真实批量 $\mathcal{X}_N$ 和一个生成批量 $\mathcal{Y}_M$ 来代替完整的分布),我们可以得到最终在代码中使用的损失函数:
\[\mathcal{L}_{\phi, \theta, \rho}(\mathcal{X}_N, \mathcal{Y}_M) = \frac{\rho}{N} \sum_{i=1}^N \sum_{j=1}^M c(x_i, y_j) \hat{\pi}_M(y_j\mid x_i, \phi) + \frac{1-\rho}{M} \sum_{j=1}^M \sum_{i=1}^N c(x_i, y_j) \hat{\pi}_N(x_i\mid y_j, \phi)\]或者写成\(\mathcal{L}_{\phi, \theta, \rho}(\mathcal{X}_N, \mathcal{Y}_M) = \sum_{i=1}^N \sum_{j=1}^M c(x_i, y_j) \left( \frac{\rho}{N} \hat{\pi}_M(y_j\mid x_i, \phi) + \frac{1-\rho}{M} \hat{\pi}_N(x_i\mid y_j, \phi) \right)\)
合作训练或对抗训练的特征编码器
我们已经成功地将CT的理论转化为一个可以在小批量样本上计算的具体损失函数。这个损失函数依赖于两个关键的函数:点对成本函数 $c(x,y)$ 和导航器中的距离函数 $d_\phi(x,y)$。
如果我们在处理像图像这样的高维复杂数据时,草率地使用原始像素间的欧氏距离来定义它们,那么整个框架的效果将会大打折扣,甚至完全失败,因为像素距离无法捕捉我们人类感知的语义相似度。
所以,我们不应该在原始的、充满噪声且语义模糊的像素空间(pixel space)中比较数据,而应该在一个更抽象、更干净、更能反映数据本质的特征空间(feature space)中进行比较。
为了实现这一目标,作者引入了一个新的神经网络,称为特征编码器 (feature encoder),记为 $T_\eta(\cdot)$。
- $T_\eta(\cdot)$:这是一个由参数 $\eta$ 控制的深度神经网络(例如一个卷积网络 CNN)。
- 功能:它的输入是一个原始数据点 $x$(例如一张 $64 \times 64 \times 3$ 的图像),输出是该数据点的一个低维特征向量(feature vector)或称为嵌入(embedding)。例如,一个128维的向量。
- 目标:这个编码器 $T_\eta$ 的目标是学习到一个优秀的特征表示 (feature representation)。在一个好的特征空间里,语义上相似的数据点(比如两张不同角度的猫的图片)在向量空间中的距离会很近,而语义上不同的数据点(一张猫和一张狗)则会很远,即使它们在像素颜色上可能很相似。
有了特征编码器 $T_\eta$ 之后,我们就可以在它创造的特征空间里重新定义我们的成本函数 $c(x,y)$ 和导航器所用的距离函数 $d_\phi(x,y)$。
公式(14): 重新定义的成本和距离
- 新的成本函数:
\(c_\eta(x, y) = 1 - \cos(T_\eta(x), T_\eta(y))\)
这里使用了余弦相异性 (cosine dissimilarity)。$\cos(\cdot, \cdot)$ 计算两个特征向量之间夹角的余弦值。
- 如果两个特征向量 $T_\eta(x)$ 和 $T_\eta(y)$ 方向几乎一致(语义上极度相似),余弦值接近1,那么成本 $c_\eta(x, y)$ 就接近0。
- 如果两个特征向量方向完全相反(语义上完全不同),余弦值接近-1,成本就接近2。 相比于欧氏距离,余弦距离更关注向量的方向而非长度,这在很多高维特征比较的任务中被证明是更鲁棒的选择。
- 新的导航器距离: \(d_{\phi, \eta}(x, y) = d_\phi\left(\frac{T_\eta(x)}{\|T_\eta(x)\|}, \frac{T_\eta(y)}{\|T_\eta(y)\|}\right)\) 这里的 $d_\phi(\cdot, \cdot)$ 仍然是另一个神经网络,但它的输入不再是原始数据,而是经过 $T_\eta$ 编码并归一化(normalization)后的特征向量。归一化(除以向量的模长 $| \cdot |$)使得 $d_\phi$ 只关注特征向量的方向信息,与上面的余弦成本保持一致。
现在,我们的最终损失函数 $\mathcal{L}$ 中所有的 $c(x_i, y_j)$ 和 $d_\phi(x_i, y_j)$ 都被替换成了它们在特征空间中的新版本 $c_\eta(x_i, y_j)$ 和 $d_{\phi, \eta}(x_i, y_j)$。
$T_\eta$的参数 $\eta$ 应该如何学习呢?作者在这里提出了两种截然不同但都非常有效的训练范式,这极大地增强了CT框架的灵活性。
范式一:对抗式训练 (Adversarially-trained)
这是最自然、也是性能通常最好的一种方式。在这种模式下,我们将特征编码器 $T_\eta$ 视为一个评判家 (Critic),它与生成器之间是一种对抗关系。
整个系统变成了一个包含三个玩家的最小-最大博弈 (Min-Max Game),如公式(15)所示:
\[\min_{\phi, \theta} \max_{\eta} \mathbb{E}_{\boldsymbol{x}_{1:N} \subseteq \mathcal{X}, \boldsymbol{\epsilon}_{1:M} \overset{i.i.d}{\sim} p(\boldsymbol{\epsilon})} \left[ \mathcal{L}_{\phi,\theta,\rho,\eta} (\boldsymbol{x}_{1:N}, \{ G_{\theta}(\boldsymbol{\epsilon}_j) \}_{j=1}^{M}) \right]\]- 玩家组合一 (最小化团队):生成器 $G_\theta$ 和 导航器网络 $d_\phi$。他们的共同目标是最小化 (min) 最终的CT损失函数 $\mathcal{L}$。他们会合作,生成更逼真的样本,并规划出成本最低的传输路径。
- 玩家二 (最大化玩家):特征编码器/评判家 $T_\eta$。它的目标是最大化 (max) 最终的CT损失函数 $\mathcal{L}$。它会想尽办法调整特征空间,将真实样本的特征 $T_\eta(x)$ 和生成样本的特征 $T_\eta(y)$ 在特征空间中推得尽可能远,从而让它们之间的成本 $c_\eta$ 和距离 $d_{\phi, \eta}$ 变得更大。
与WGAN的对比和优势: WGAN中的Critic也扮演了类似的角色。但CT的一个显著优势是,特征编码器 $T_\eta$ 的更新不需要与生成器 $G_\theta$ 的更新进行严格的同步或平衡。在WGAN中,如果Critic更新太多次或太少次,训练很容易崩溃。而论文指出,CT的训练过程要稳定得多,编码器的更新可以更自由,甚至可以在训练中途“冻结”住,整个系统依然能稳定工作。
范式二:合作式训练 (Cooperatively-trained)
这是CT方法一个非常新颖和灵活的特性。特征编码器 $T_\eta$ 不一定非要和生成器“对着干”,它可以是一个“第三方专家”,以一种合作的方式提供一个高质量的特征空间。
- 解耦训练:我们将 $T_\eta$ 的训练和 $G_\theta$ 的训练进行解耦。
- 训练 $T_\eta$:我们使用另外一个成熟的损失函数来单独训练 $T_\eta$。例如:
- GAN判别器损失:我们可以让 $T_\eta$ 同时扮演一个标准的GAN判别器的角色,训练它来完成“判断真伪”的二分类任务。这个任务本身就能迫使 $T_\eta$ 学会强大的特征提取能力。
- WGAN评判家损失:同理,也可以用WGAN的损失来训练它。
- MMD损失:甚至可以用MMD-GAN的损失来训练它。
- 训练 $G_\theta$:在训练生成器时,我们利用这个由其他任务训练好的 $T_\eta$ 所提供的特征空间,在这个(可能是固定的,也可能在缓慢更新的)特征空间里,用我们的CT损失函数 $\mathcal{L}$ 来优化生成器 $G_\theta$ 和导航器 $d_\phi$。
这种合作模式有什么好处?
- 稳定性:它避免了复杂的最小-最大博弈动态,训练过程通常更稳定。
- 灵活性:我们可以“借用”其他领域已经训练好的、非常强大的预训练编码器(比如在ImageNet上训练的ResNet)来作为我们的 $T_\eta$,这被称为迁移学习(Transfer Learning)。这使得CT可以轻松地利用海量外部知识,这在数据量有限的情况下尤其有用。
- 模块化:它将“学习一个好的特征空间”和“在该空间中度量分布差异”这两个任务分离开来,使得系统更加模块化,易于分析和调试。
对抗式训练通常能取得最好的性能,因为它为CT任务“量身定做”了一个最困难的特征空间。但合作式训练同样非常有效,并且也能够显著提升基线模型的性能,这展示了CT框架强大的兼容性和灵活性。
实验
4.1 前向与后向分析 (Forward and backward analysis)
- 实验设计:
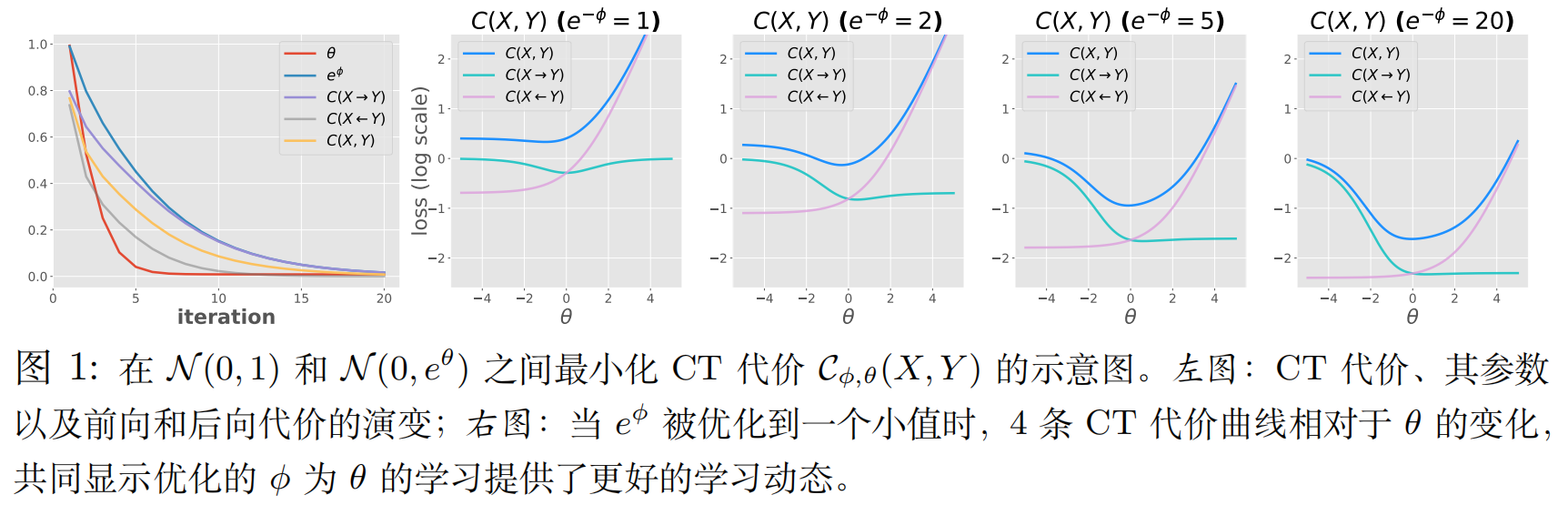
- 数据集:作者选用了两个经典的“多模式”数据集:一个是一维的双峰高斯混合分布(有两个“山头”),另一个是二维的八点高斯混合分布(围成一圈的八个“点簇”)。检验模型是否会模式崩塌。
- 控制变量:作者通过调节我们之前讨论过的平衡参数 $\rho$(从1到0),来观察生成器行为的变化。$\rho=1$代表纯前向(模式覆盖),$\rho=0$代表纯后向(模式搜寻)。
结论:前向成本驱动模式覆盖,后向成本驱动模式搜寻,而将两者结合能够有效地平衡两者,抵抗模式崩塌。
4.2 抵抗模式崩塌 (Resistance to mode collapse)
这个实验进一步强化了CT在抵抗模式崩塌方面的优势,尤其是在数据不均衡的情况下。
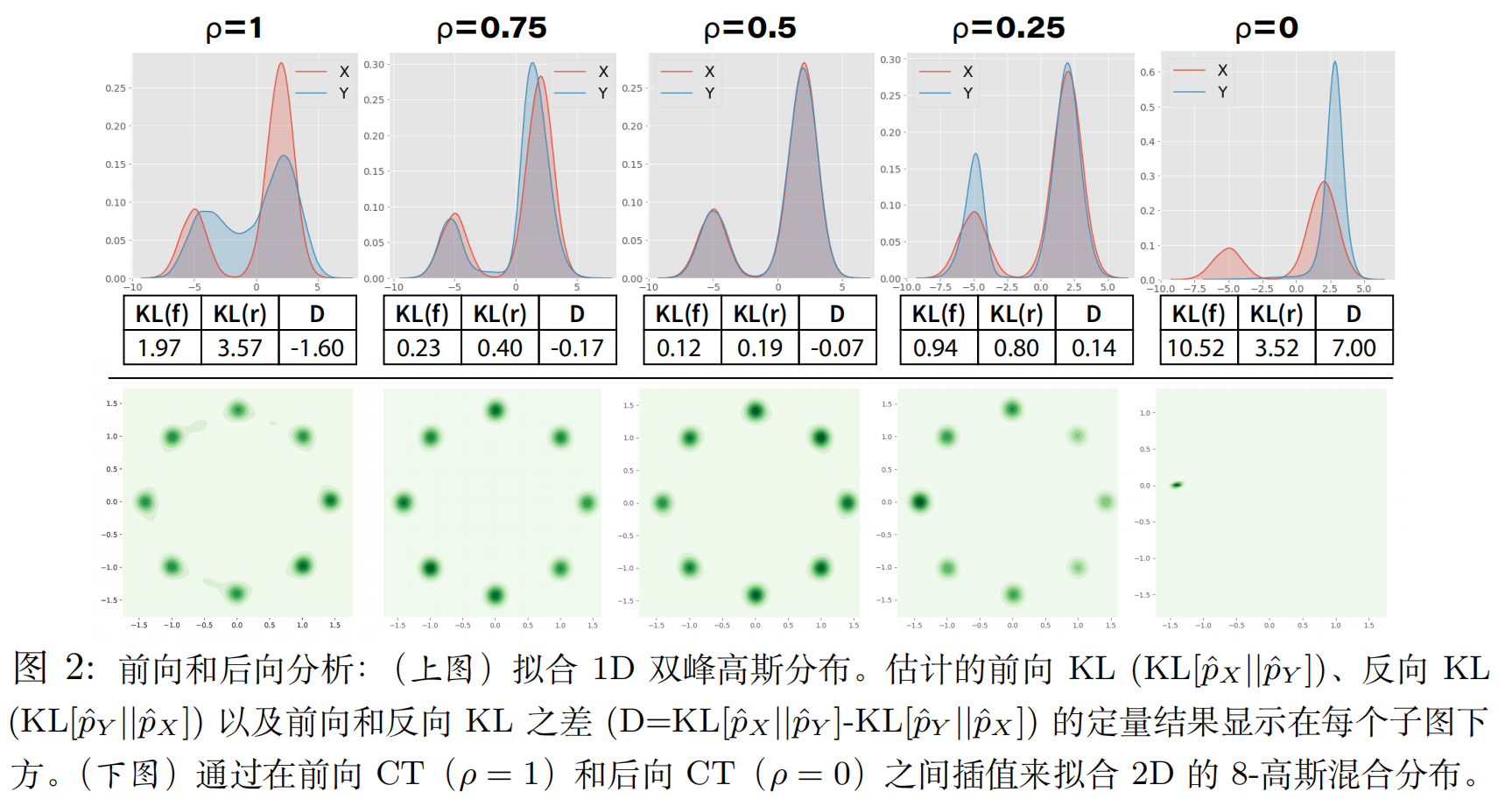
- 实验设计:
- 数据集:仍然是8-高斯混合分布,但这次不是所有模式都一样重要。作者将左下角的那个模式的权重 $\gamma$ 设得非常小(例如 $\gamma=0.05$),而其他7个模式平分剩下的0.95的权重。这是一个非常苛刻的测试,因为那个“少数派”模式在小批量采样中出现的频率会很低。
- 对比模型:CT与标准的GAN, WGAN-GP, SWD(一种基于切片Wasserstein距离的方法)进行对比。
- **结果与分析 **:
- 当 $\gamma=0.05$(左下角模式是少数派)时,GAN, WGAN-GP, SWD全都忽略了这个模式。 它们的生成结果中,左下角是空的。这是因为在训练中,它们很少见到这个模式的样本,就“认为”它不重要或者不存在。
- 只有CT(ours)成功地捕捉到了这个少数派模式。
- 为什么CT能做到? 论文解释说,这归功于前向成本的模式覆盖特性。即使某个模式的样本很少见,但它终究是真实数据的一部分 ($p_x>0$)。只要CT的前向成本存在,模型就会因为“没有覆盖到这个真实区域”而受到惩罚(产生很高的成本),从而被迫去学习这个模式。后向成本则进一步帮助模型精确地定位这个模式的密度。
- 反之,当 $\gamma=0.5$(左下角模式是“多数派”)时,其他模型又倾向于忽略那些“少数派”模式,而CT依然能捕捉到所有模式。
- 本节结论:CT在处理不均衡的多模式数据时,表现出比其他主流方法更强的鲁棒性,能有效抵抗因数据不均衡导致的模式崩塌。
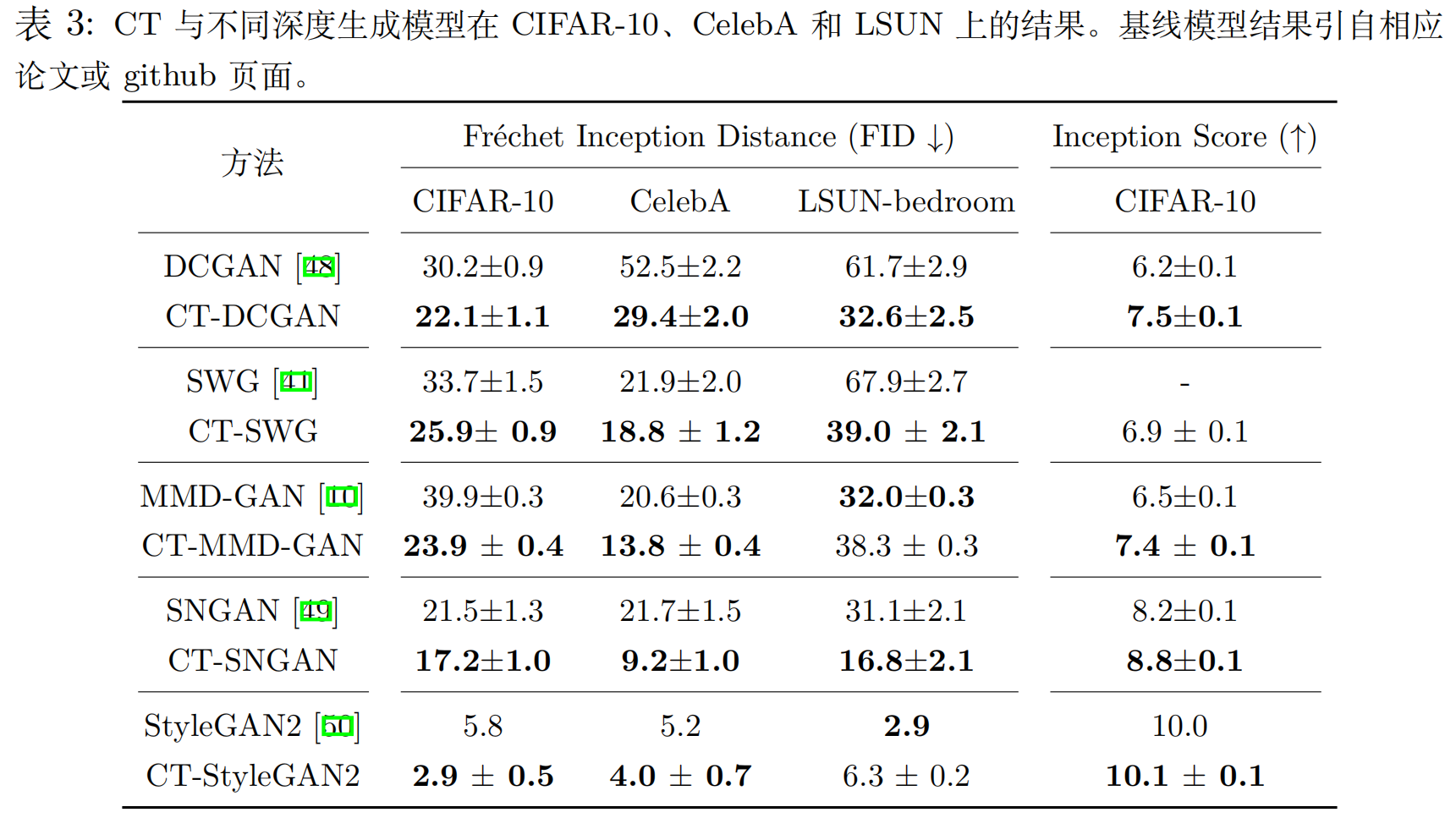
4.3 真实图像上的性能对比 (Adversarially-trained CT for natural images)
4.4 关于平衡参数 $\rho$ 的选择 (On the choice of $\rho$)