NewtonGen:通过神经牛顿动力学实现物理一致且可控的文本到视频生成
NewtonGen: Physics-Consistent and Controllable Text-to-Video Generation via Neural Newtonian Dynamics
Background
当今AI视频生成技术遇到了两个问题:
- 物理一致性 (Physical Consistency):如何保证符合生活常识和物理规律
- 参数可控性 (Parameter Controllability):如何精确地控制视频里物体的运动轨迹、速度等参数
现有的文本到视频模型缺乏对内在物理定律的理解,模型主要依赖于记忆和模仿,这使得它很难泛化到分布外的场景。
为了解决上述问题,作者提出了一个名叫 NewtonGen 的新框架:
-
物理大脑 (NND模块):专门训练一个“懂物理”的小模型,作者称之为神经牛顿动力学 (Neural Newtonian Dynamics, NND)。这个小模型不负责画画,只负责一件事:预测物体的运动轨迹。给它一个物体的初始状态(比如位置、速度),它就能像物理引擎一样,计算出下一秒、再下一秒……物体应该在哪个位置,速度是多少。
-
绘画大师 (视频生成模型):使用一个现成的、强大的视频生成模型。这个模型非常擅长“画画”,能根据文字描述生成精美的画面,但它不懂物理。
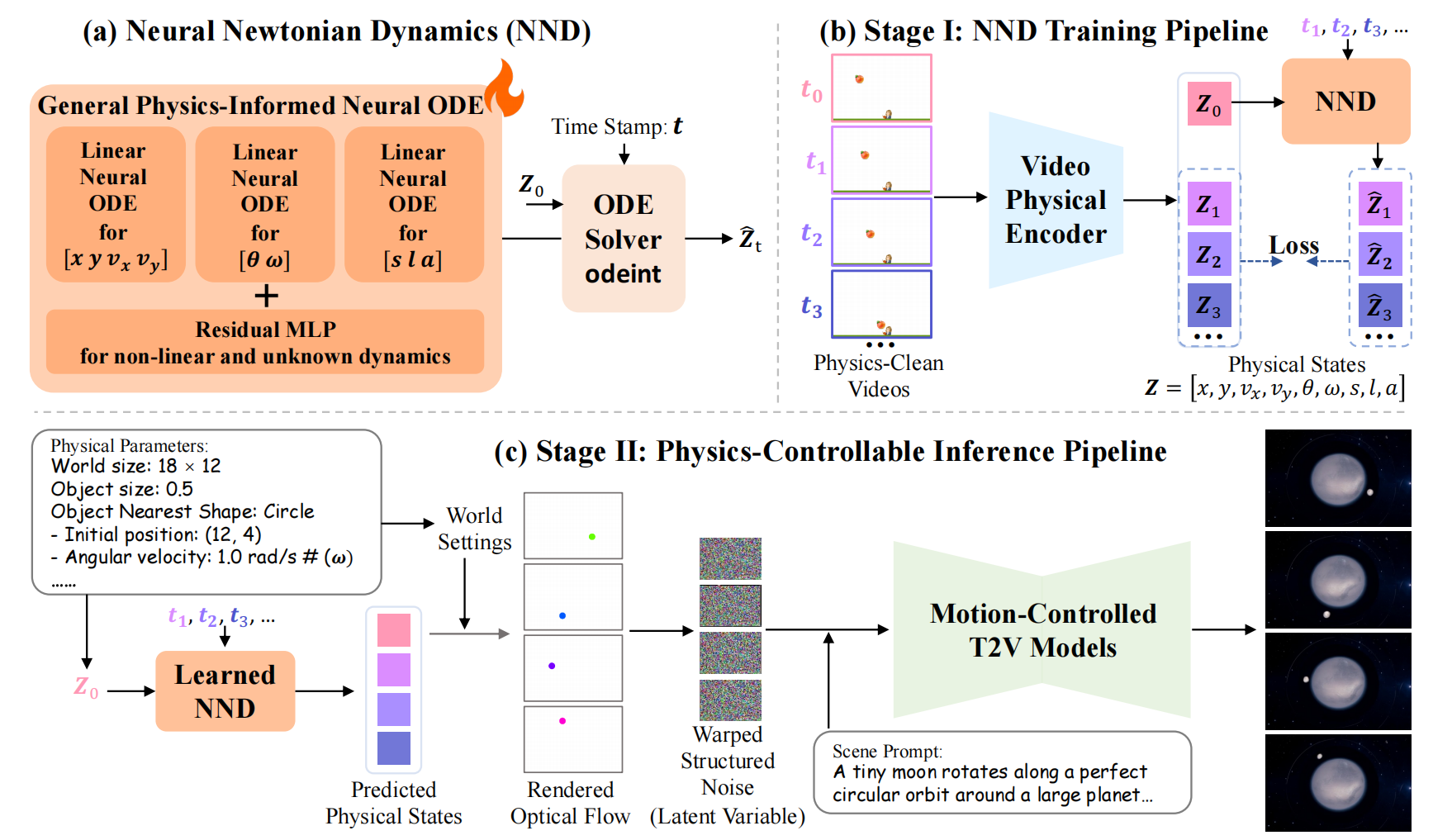
NewtonGen工作过程分为两个阶段:
- 第一阶段:训练“物理大脑”
- 作者自己用程序模拟制作了很多“物理干净”的视频。所谓“干净”,就是视频里的物体运动完全符合物理公式,没有模糊、没有遮挡,非常标准。就像物理课本里的标准例题一样。
- 让NND这个“物理大脑”去学习这些标准视频,目标是让它学会准确预测物体的运动。
- 第二阶段:生成视频
- 用户下达指令:你输入文字,比如“一个篮球飞向篮筐”,同时可以指定物理参数,比如“初始位置在(x, y),初始速度是(vx, vy)”。
- “物理大脑”出马:训练好的NND接收到这些物理参数后,立刻开始计算,预测出篮球在接下来每一帧画面中的精确位置、朝向、大小等状态。它输出的不是图像,而是一系列物理状态数据。
- 数据“翻译”:将NND输出的这些物理状态数据,转换成一种叫做“光流 (Optical Flow)”的东西。可以简单理解为“运动草稿”,它描述了画面中每个像素点应该往哪个方向移动。
- “绘画大师”上色:最后,把你的文字描述(比如“在一个晴朗的室外篮球场”)和这个“运动草稿”(光流)一起交给“绘画大师”(视频生成模型)。绘画大师就会一边根据文字画出篮球场的背景,一边严格按照运动草稿来画篮球的每一帧,确保篮球的运动是完全符合物理规律的。
神经牛顿动力学(NND)
物理状态向量
为了用数学来描述一个物体的运动,我们首先需要定义清楚要追踪哪些物理量。NND定义了一个包含9个维度的“潜在物理状态向量” $Z$ 来全面捕捉物体的状态。这就像是给物体填一张体检表,上面有9个项目:
$Z = [x, y, v_x, v_y, \theta, \omega, s, l, a]$
我们来逐一解释这9个项目:
- $x, y$: 物体中心在二维平面上的位置坐标。
- $v_x, v_y$: 物体中心在x和y方向上的速度。
- $\theta$: 物体的旋转角度。比如一个木棍是横着放还是竖着放。
- $\omega$: 物体的角速度,也就是它旋转的快慢。
- $s$: 物体的短轴长度 (shortest dimension)。
- $l$: 物体的长轴长度 (longest dimension)。
- $a$: 物体的投影面积。
在现实世界中,一个物体可能会旋转(需要$\theta, \omega$)、变形或者在3D空间里有远近变化(这些都可以通过$s, l, a$的变化来近似模拟)。这个9维向量的设计,使得NND有能力去理解和预测不仅仅是平移,还包括旋转、变形等更复杂的运动。
带有残差 MLP 的线性物理信息神经 ODE
现在我们有了描述物体状态的向量$Z$。接下来的问题是:如果我知道物体在这一刻的状态$Z_t$,如何预测它在下一刻的状态$Z_{t+1}$? 这就需要一个描述“变化规律”的方程。
物理学的核心就是用微分方程来描述变化。这篇论文的核心数学模型就是一个常微分方程 (Ordinary Differential Equation, ODE)。它的本质就是:一个描述“事物当前的变化率”与“事物当前的状态”之间关系的方程。
知道了变化率,我们就可以通过积分(累加这些微小的变化)来预测未来的状态。
但是,不同的运动(比如自由落体和弹簧振动)遵循的物理规律(也就是ODE)是不同的。作者如何设计一个能“通吃”多种运动的通用ODE框架呢?他们采用了“线性模型 + 非线性修正”的巧妙思想,具体体现在论文的公式(4)中:
$a_z \ddot{z} + b_z \dot{z} + c_z z + d_z + \text{MLP}(Z) = 0$
- $z$: 代表我们关心的9维状态向量$Z$中的任意一个维度。比如,它可以是x方向的位置$x$,或者是旋转角度$\theta$。
- $\dot{z}$ (读作 “z dot”): 这是$z$对时间的一阶导数,代表速度。如果$z$是位置$x$,那么$\dot{z}$就是速度$v_x$。
- $\ddot{z}$ (读作 “z double dot”): 这是$z$对时间的二阶导数,代表加速度。如果$z$是位置$x$,那么$\ddot{z}$就是加速度$a_x$。
- $a_z, b_z, c_z, d_z$: 这四个是可学习的参数。可以把它们想象成四个可以调节的“旋钮”。通过在训练中不断调整这四个旋钮的数值,模型就可以模拟出很多基础的、线性的物理运动。
- 例如,对于匀速运动,加速度为0,模型会学会让$\ddot{z}$相关的项等于0。
- 对于自由落体,加速度是常数$g$,模型会学会调整参数,让$\ddot{z}$等于一个接近$g$的值。
- 对于弹簧振动(简谐运动),其受力满足$F = -kx$,加速度$a = -(k/m)x$,这个方程的形式和公式(4)的线性部分很像。
- $\text{MLP}(Z)$: 这是整个公式的点睛之笔。MLP (Multi-Layer Perceptron) 是一个标准的神经网络。它的作用是修正和补充。
- 前面那个线性部分($a_z \ddot{z} + …$)虽然能模拟很多基础物理,但对于复杂的、非线性的情况(比如空气阻力、摩擦力,或者一些未知的复杂动力学)就无能为力了。
- MLP这个神经网络的作用,就是根据物体当前完整的9维状态$Z$,去学习和预测那些线性部分无法描述的复杂力量,并给出一个修正项。
公式(4)的白话翻译: “一个物体在某个维度上的运动规律,可以被一个‘基础物理公式模板’(线性部分)和一个‘高级修正专家’(MLP神经网络)共同决定。前者负责简单、普适的规律,后者负责复杂、特殊的情况。”
通过这个设计,NND框架变得既有物理学赋予的结构性(线性部分),又有神经网络带来的灵活性和强大拟合能力(MLP部分)。
有了描述变化率的规则(公式4),我们就可以用公式(5)来预测未来:
$Z_t = Z_0 + \int_{t_0}^t \text{Func}(Z(\tau)) d\tau$
- $Z_t$: 我们想要预测的、在未来$t$时刻的物体状态。
- $Z_0$: 物体的初始状态(在$t_0$时刻)。
- $\text{Func}(Z(\tau))$: 这代表了在任意时刻$\tau$,物体的状态$Z(\tau)$的变化率是多少。
- $\int_{t_0}^t … d\tau$: 这是积分符号,在这里你可以简单理解为“从初始时刻$t_0$到未来时刻$t$,把所有微小时间段内的变化量累加起来”。
“要想知道物体未来的状态($Z_t$),你只需要在它的初始状态($Z_0$)的基础上,把遵循物理规律(Func)产生的每一瞬间的微小变化,从开始一直累加到那个未来时刻。”
在实际计算中,这个积分过程是由一个叫做ODE求解器 (ODE Solver) 的现成工具来完成的。
NND训练:只做“编码”,不做“解码”
现在我们知道了NND的模型结构,那么它是如何学习那些参数($a_z,b_z,c_z,d_z$和MLP里的权重)的呢?
训练流程非常直接:
- 准备数据:使用前面提到的“物理干净”的模拟视频。
- 提取“标准答案”:用一个叫做视频物理编码器 ($E_{phys}$) 的工具,逐帧分析视频,提取出每一帧的真实物理状态$Z_t$。这些就是NND需要学习的“标准答案”。这个编码器是基于一些成熟的计算机视觉技术(如图像分割)实现的,可以精确计算出视频中物体的位置、速度、形状等。
- 进行“模拟考试”:
- 把视频的第一帧的真实物理状态$Z_0$作为初始条件,输入给NND。
- 让NND使用它的ODE模型(公式4和5),一口气预测出后面所有帧的物理状态,我们称之为预测值$\hat{Z}_t$。
- 批改“试卷”:
- 比较NND的预测值$\hat{Z}_t$和从视频中提取的“标准答案”$Z_t$。
- 计算两者之间的差距,这个差距在机器学习中称为损失 (Loss)。
- 订正和提高:使用优化算法(比如梯度下降),根据损失的大小,反向微调NND内部的所有可学习参数,目标是让损失越来越小。
- 重复练习:在整个数据集上成千上万次地重复上述过程,直到NND的预测足够准确。
这里有一个关键点:这个训练架构是“仅编码器” (Encoder-Only) 的。也就是说,我们只需要从视频中“编码”出物理状态,而不需要一个“解码器”再把物理状态变回视频画面。这使得训练过程非常轻量和高效,因为它只在抽象的9维物理空间中进行计算,而不用处理高维度的像素数据。
物理可控文本到视频生成
我们已经拥有了一个强大的NND模型。你给它一个物体的初始状态($Z_0 = [x_0, y_0, v_{x0}, …]$)和一系列时间点($t_1, t_2, …$),它就能立刻预测出这些时间点上物体对应的物理状态($Z_1, Z_2, …$)。
现在的问题是,如何把这些抽象的物理数据,转化成生动、具体的视频画面?
这就是“绘画大师”(一个预训练好的文本到视频生成模型)登场的时候了。但是,我们不能直接把一堆数字($Z_t$)丢给它,它看不懂。我们需要一个“翻译官”,把物理数据翻译成视频模型能理解的“语言”。
翻译官:从物理状态到光流 (Optical Flow)
视频模型能理解的一种强大的运动控制语言叫做光流 (Optical Flow)。
- 什么是光流?
你可以把它想象成一个箭头场。对于视频的某一帧,光流图会为图中的每一个(或一部分)像素点都画上一个箭头,这个箭头指示了该像素点在下一帧中应该移动的方向和距离。
- 箭头长,表示移动速度快。
- 箭头指向右上方,表示像素向右上方移动。
如果有了每一帧之间的精确光流,视频生成模型就能像做“连连看”一样,确保物体在帧与帧之间的移动是平滑且正确的。
NewtonGen的推理(生成视频)流程
- 用户输入:
- 场景提示 (Scene Prompt):一段文字,描述视频的场景和内容。例如:“一只足球在一个绿茵场上做抛物线运动”。
- 物理参数 (Physical Parameters):用户指定的精确初始条件。例如:
初始位置=(2, 10),初始速度=(5, -0.8)。
- “物理大脑”预测:
- 首先,程序会解析用户的物理参数,得到初始状态向量$Z_0$。
- 将$Z_0$输入到我们训练好的NND模型中。
- NND预测出视频未来每一帧(比如总共16帧)对应的物理状态序列:$Z_1, Z_2, …, Z_{16}$。
- “翻译官”工作:
- 现在我们有了一系列精确的物理状态$Z_t$。对于每一对连续的帧(比如第$t$帧和第$t+1$帧),我们可以根据$Z_t$和$Z_{t+1}$计算出物体在这两帧之间的运动。
- 例如,从$Z_t$和$Z_{t+1}$中可以读出物体中心位置的变化、旋转角度的变化、大小的变化等。
- 基于这些变化,程序会计算出一个近似的光流场。这个光流场描述了物体的整体运动。
- “绘画大师”渲染:
- 最后一步,将三样东西一同交给基础视频生成模型(论文中用的是一个叫做
Go-with-the-Flow的模型,它恰好擅长利用光流来控制运动):- 场景提示文本:“一只足球在一个绿茵场上…”
- 计算出的光流序列:指导足球如何运动。
- 初始噪声:这是扩散模型生成多样性画面的基础。通过对光流进行扭曲(warp)来处理噪声,可以确保运动在时间上的连贯性。
- 视频生成模型接收到指令后,就会开始“绘画”。它一边根据文本来绘制绿茵场、足球的外观、光影等,一边严格遵循光流的指导来移动足球的位置,最终生成一段物理上完全符合NND预测的视频。
- 最后一步,将三样东西一同交给基础视频生成模型(论文中用的是一个叫做
这个流程的精妙之处在于“解耦” (Decoupling):
- 物理推理(NND做什么)和视频渲染(生成模型做什么)被彻底分开了。
- NND专注于它最擅长的——精确的动力学计算。
- 视频生成模型专注于它最擅长的——生成高质量、符合文本描述的画面。
- 这种分工使得整个系统既准确又灵活。例如,我们可以保持相同的物理参数,只改变场景描述(从“足球场”到“沙滩”),NND的计算结果完全不用变,最终就能生成足球在沙滩上做同样抛物线运动的视频(如论文图30所示)。
实验效果:NewtonGen真的有效吗?
这篇论文的强大之处不仅在于提出了一个好想法,更在于通过详尽的实验证明了它的有效性。
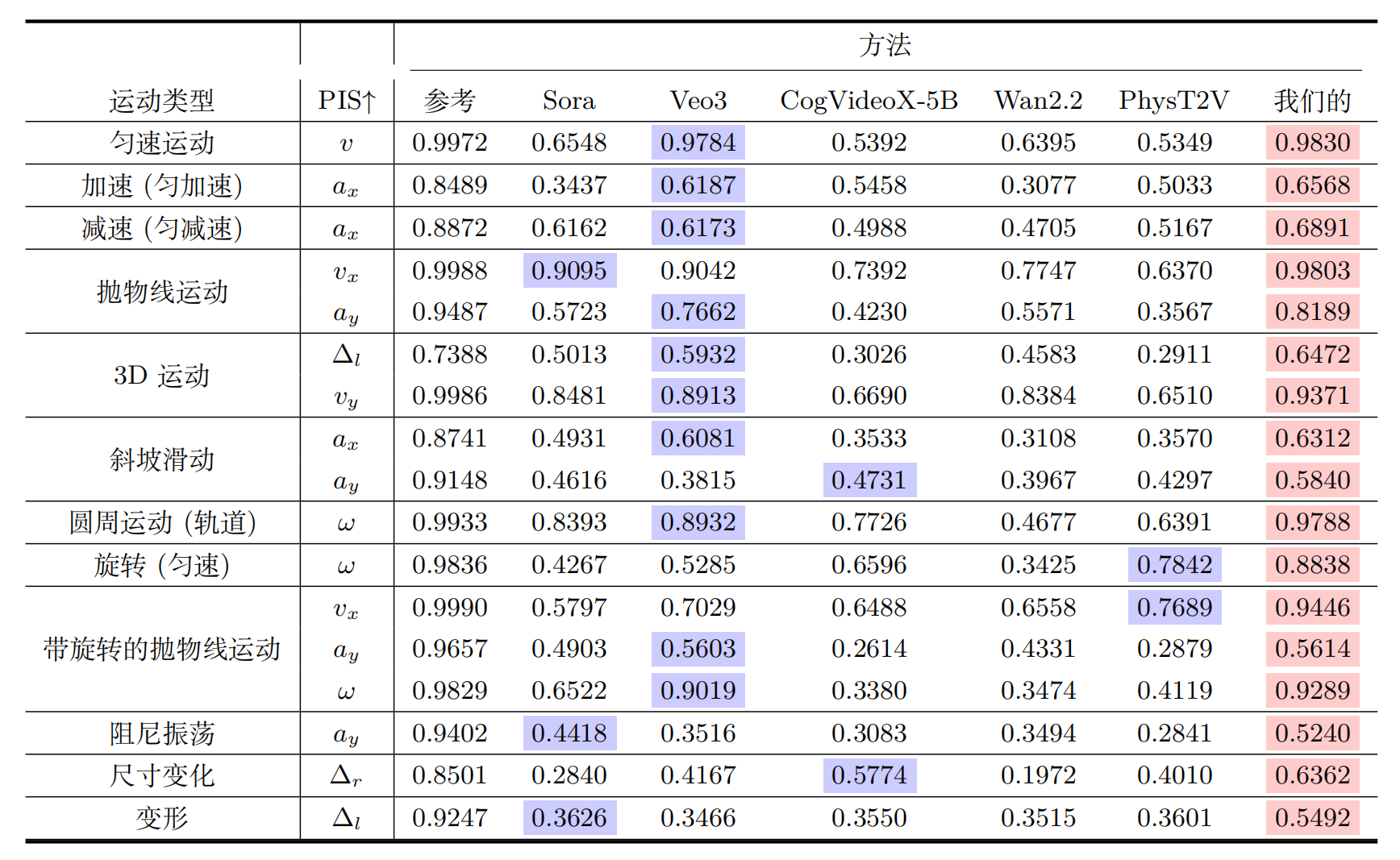
物理一致性对比 (论文表1和图3)
-
如何衡量“物理一致性”? 这是一个难题,因为AI生成的视频没有绝对的“正确答案”。作者借鉴并提出了一个叫做物理不变性分数 (Physical Invariance Score, PIS) 的指标。
- 核心思想:在很多理想的物理运动中,某些物理量应该是保持不变的。
- 匀速运动:水平速度$v_x$应该不变。
- 抛物线运动:水平速度$v_x$和垂直加速度$a_y$(即重力加速度)应该不变。
- 匀速圆周运动:角速度$\omega$应该不变。
- 计算方法:通过视频分析工具,测量出这些本应不变的量在整个视频中的波动程度。波动越小,说明运动越符合物理规律,PIS分数就越高(最高为1)。
- 核心思想:在很多理想的物理运动中,某些物理量应该是保持不变的。
-
实验结果:
- 在论文的表1中,作者对比了NewtonGen和当时其他顶尖模型(Sora, Veo3等)在12种不同运动类型上的PIS分数。
-
结果非常惊人:在几乎所有运动类型上,NewtonGen的得分都遥遥领先,并且非常接近“参考值”(也就是用物理模拟器生成的完美视频的得分)。这强有力地证明了NewtonGen在物理一致性上的巨大优势。
- 图3则直观地展示了视觉对比。你可以看到,对于同样的文字提示,其他模型生成的视频中物体运动轨迹扭曲、速度突变,而NewtonGen生成的视频则平滑、逼真,完全符合物理直觉。

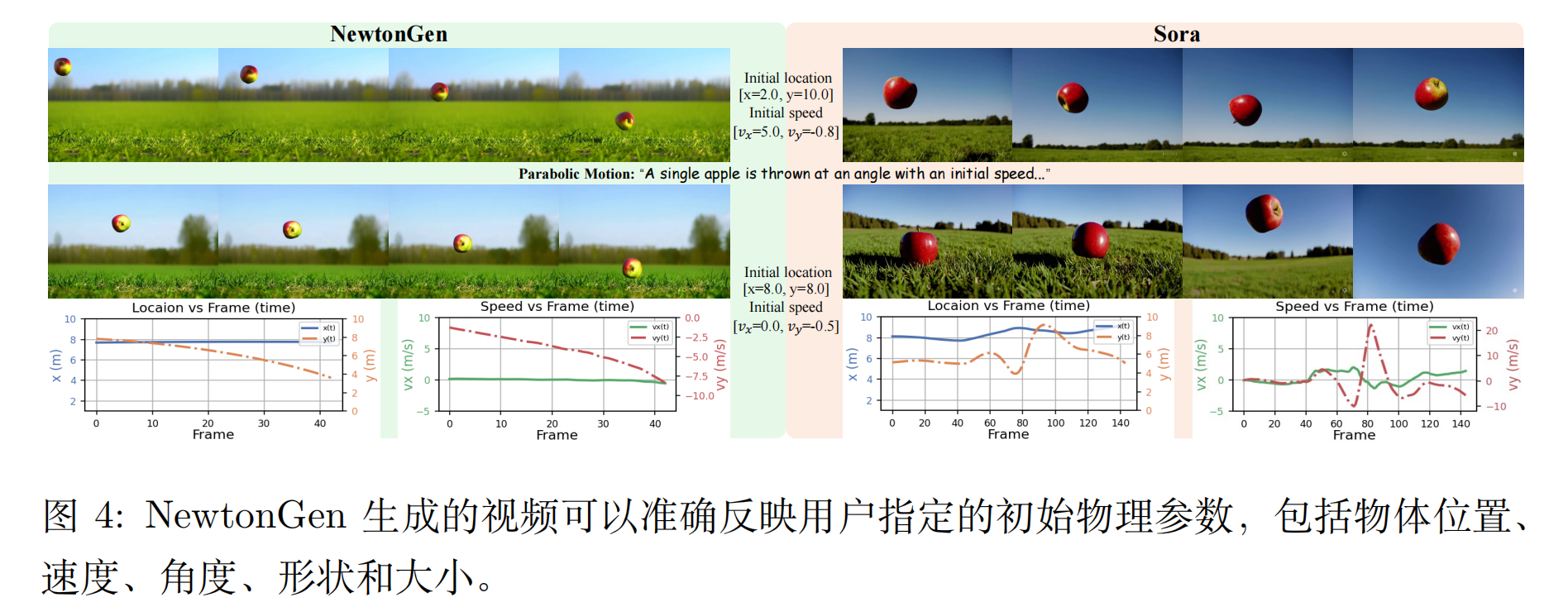
参数可控性展示
消融实验
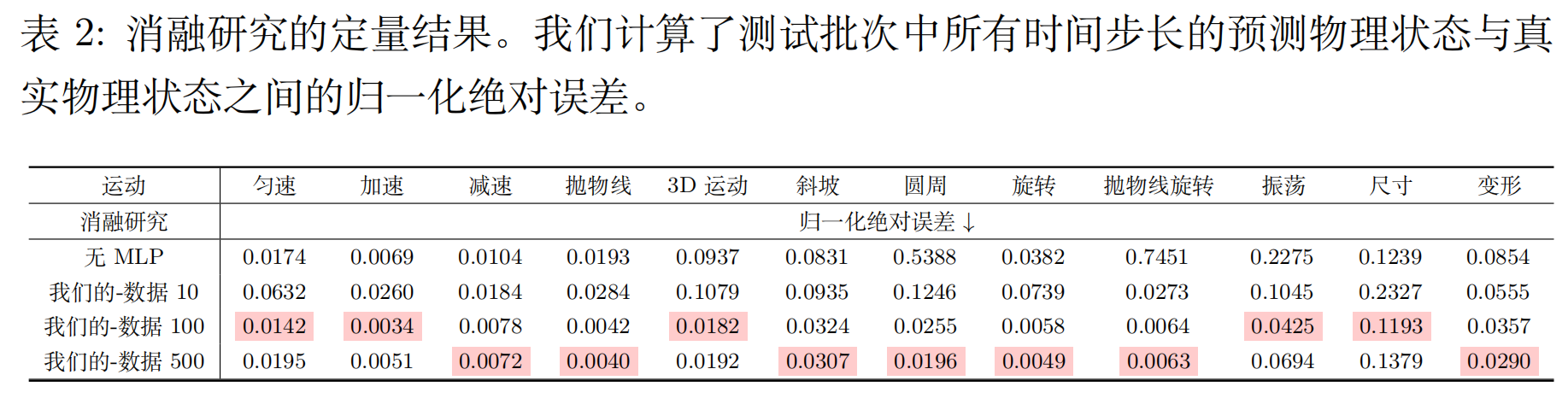
添加 MLP 显著提高了 NND 在非线性动力学和噪声数据上的性能。增加训练数据集的大小并没有带来显著的增益,这表明 NND 可以从相对少量的物理干净样本中准确推断出内在的系统动力学。
局限性
作者在论文的第7节也很诚实地指出了模型的局限性:NND是基于连续的ODE设计的,因此它不擅长处理非连续的事件,比如两个物体的碰撞、反弹或者合并等。期望未来的工作能够结合基于事件或离散的神经架构来解决这些局限性。